Tip On How To Invest In Software Testing Career Change
TL;DR In the previous post, we explained the importance of the software testing market. Let’s explain how to make a decision on which software testing domain and technology to invest….



TL;DR In the previous post, we explained the importance of the software testing market. Let’s explain how to make a decision on which software testing domain and technology to invest….

TL;DR This post is an example of real testing. Point is that you should be aware of fact that device simulators are not the same as real devices. From the…

TL;DR I use for programming emacs through spacemacs. For searching and refactoring I use grep and sed, powerful and fast utilities, but complex and with steep learning curve. This post…

TL;DR This post is my comment on letter D in S.A.C.R.E.D. mnemonic created by Friendly tester. Comment was triggered by Ben Simo tweet: “If you know the result, then it…

TL;DR This post is follow up on blog post on Testival meetup #49 where I wrote my comments on second talk, Leda Link (Infobip): Tests Storytelling. The point of this…
learn testing, ruby, testing tool
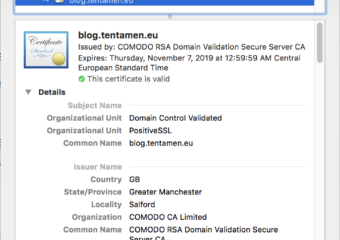
TL;DR This post is solution how to handle error “Hostname Does Not Match The Server Certificate” in Ruby. Problem Every SSL certificate has, among other information, signed site domain name….
elixir, learn testing, testing tool
TL;DR This post is short report about Zagreb Elixir Meetup #1. Elixir is functional programming language, it uses Ruby code style, and it runs on BEAM (Erlang) virtual machine. Very…

BBST, BBST Foundations, testing tool
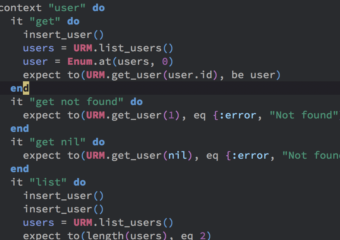
TL;DR This post explains what is programmer testing according to Black Box Software Testing Foundations course (BBST) created by Rebecca Fiedler, Cem Kaner and James Bach. Definition In Agile lifecycle…
BBST, learn testing, testing tool
TL;DR In todays software development, unit testing become synonym for software testing. It is even worse, when one unit testing library for specific language, becomes synonym for unit software testing,…

BBST Foundations, learn testing, testing tool
TL;DR This is example of resolving software testing problem using Super Auto Refresh Plus Chrome Extension. Bug Description Imagine internal application where every html button press triggers long transaction. Html…
