



TL;DR
In the previous post, we gave a report on Evolve or Die: Testing Must Change by Peter Walen, the final day’s first session. Today we report on the second session, Observability for Performance Testers by Mark Tomlinson. How observability IS different from monitoring.
Takeaways
What’s all the buzz about #olly (observability) with all this “needle in the haystack” and “digging in” and “observing stuff” language? Haven’t we been doing this with our monitoring and logging and diagnostics tools already? And what does this have to do with pre-release performance engineering, testing, and systems design? Well, I recently had a wake-up call about observability, and I’d like to share what I learned with you. How it IS different from what we do today. How you can leverage ideas about observability in your performance work. And how you’ll find you might already be doing these things without even knowing it!
Another Evolution
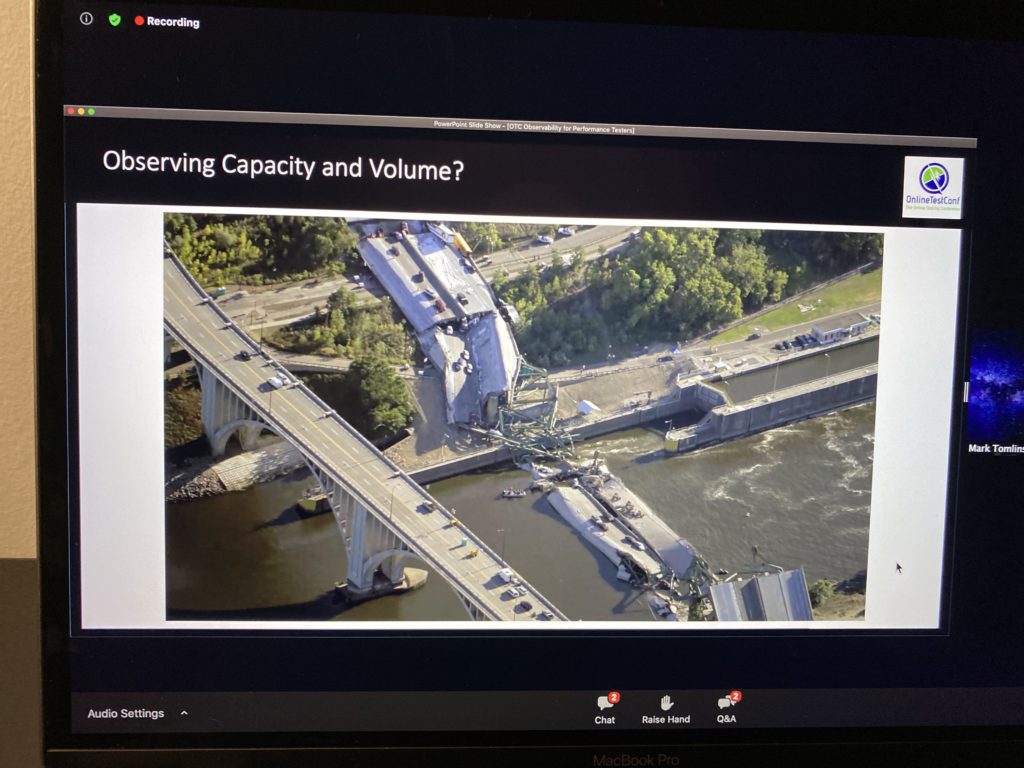
As Pete, Mark also starts with evolution, this time, the evolution of observability. An example of observability evolution was a car speedometer. The first cars were so slow, so we did not need any speedometers. As cars were faster and faster, they got speedometers. Actually, speedometers are estimators. First, speedometers were analog. Then we switched to digital. Today, we use GPS signals to estimate (very precisely) car speed.
Computer Observability
We first had monitoring:
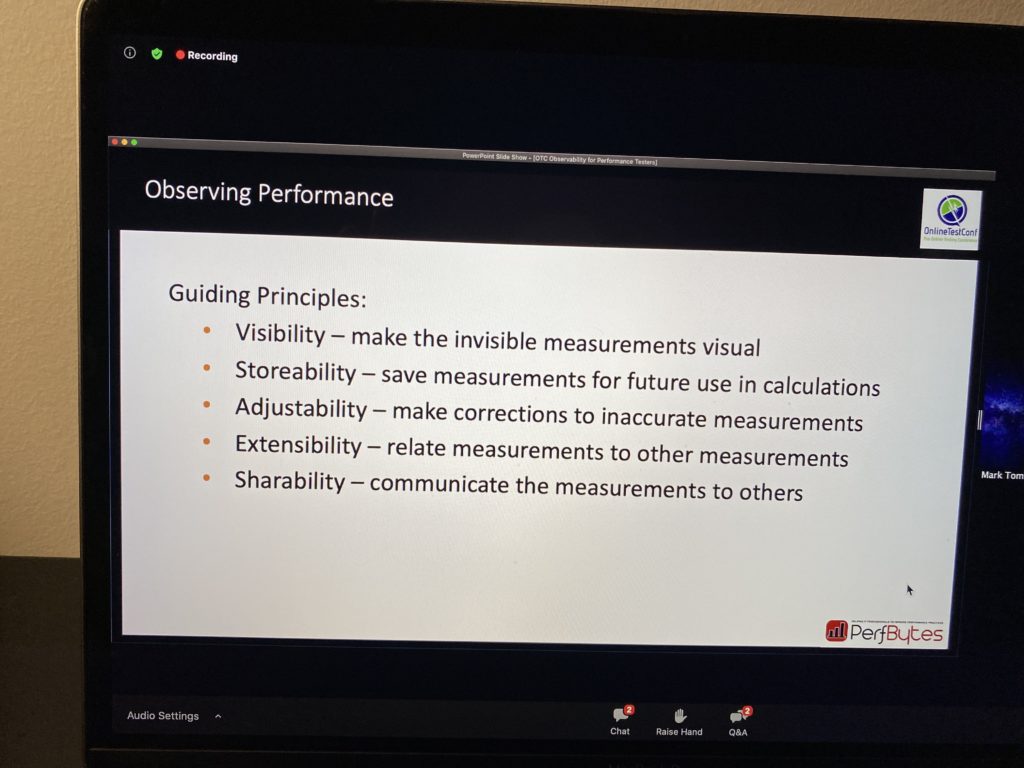
Start with five guiding principles:
Telemetry Data
Gathered telemetry data about the system should be read-only available to all team members. All team members must profit from telemetry data.
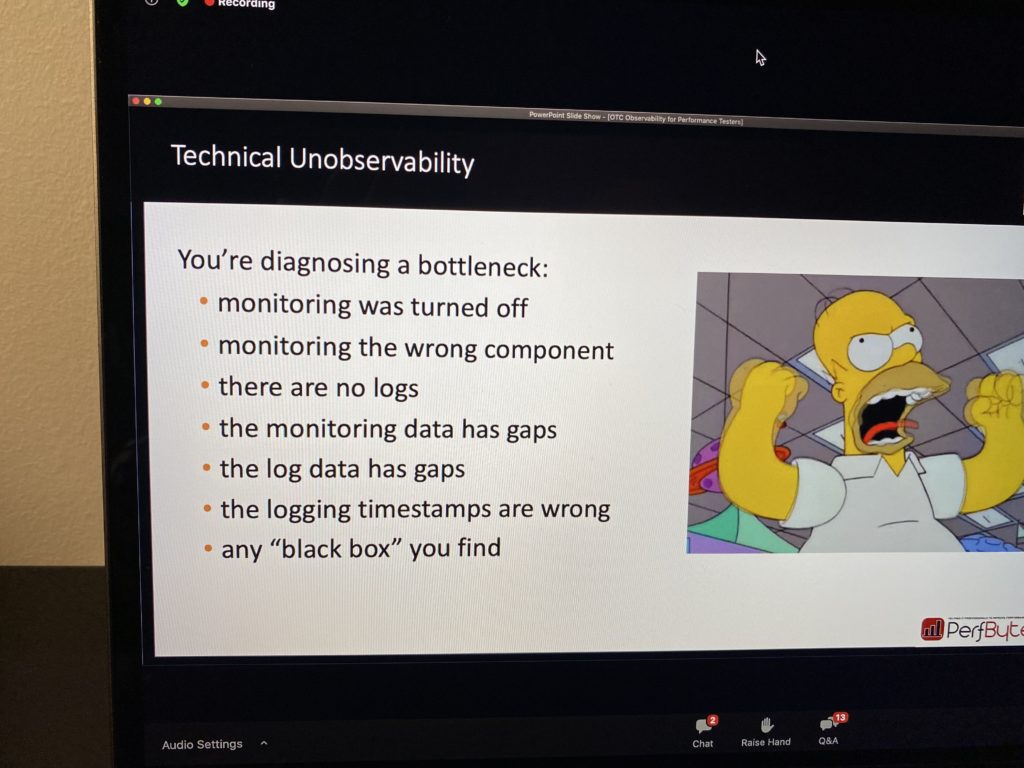
Observability Antipatterns
As with any practice, observability also has antipatterns:
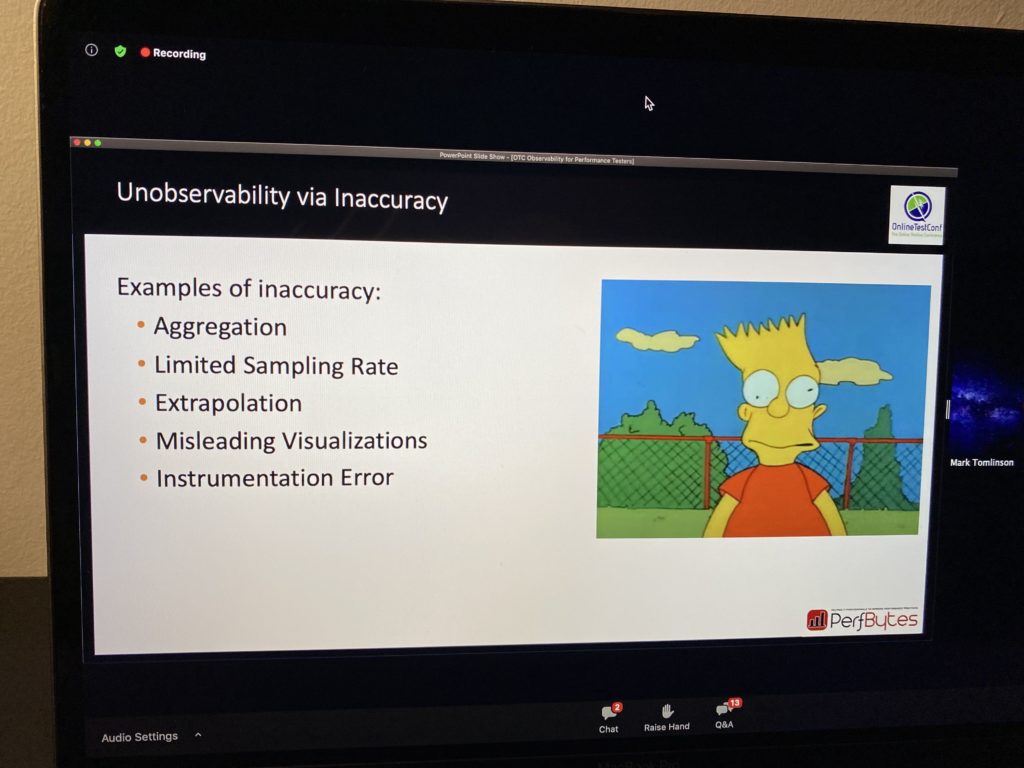
Tune Your Telemetry
You must tune up your telemetry. Otherwise, you will get inaccurate data. I remember one example where WebSockets were implemented with a long pool option of forty seconds. We could only see these forty seconds HTTP responses in the monitoring tool because everything else was masked with this long pool.
Old Vs. New School
Mark nicely compares what did and how we should do it:

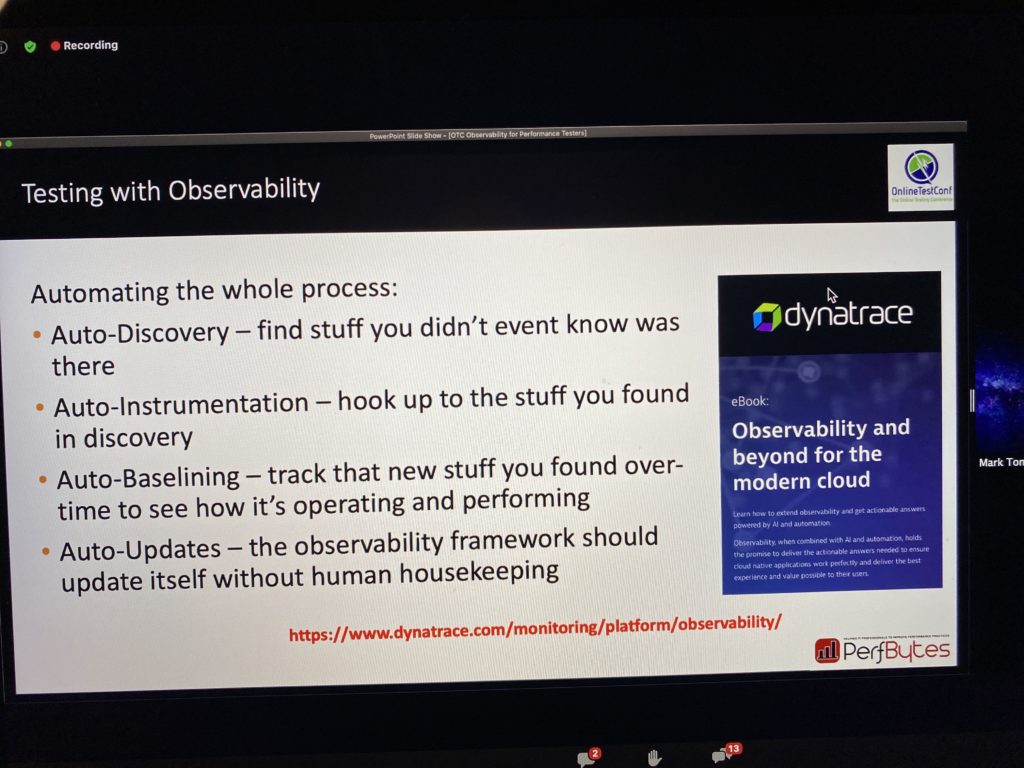
How To Test With Observability
Here is a list of recipes:
- Make it easy to operate your application.
- Timestamp 3rds party remote calls.
- Database calls
- Data transfer volume
- Expose timings for the most important features of the app
- Logs should be dumb
Dumb Logs
This acronym helps us to remember how we should log events:
- D debug mode is not required.
- U universal format simple access
- M manageable size storage and archive
- B business-relevant no decoding needed.
What To Monitor Recipe

Recipe Alert has an event unique id that could be easily traced through the whole system, end-to-end.
Recipe Alert, Instrument method level calls.
Recipe Alert, Do not instrument exception handling code.
Instrumentation is code base modification, so we have a call trace breadcrumbs in log files. Exception handling already does that out of the box, so we do not need code duplicates.
Book Alert
If you need to start with observability, why not to start with a book:
Observability Is Not Troubleshooting
Ok, this session required some knowledge on system parameters that engineers love to count and catalog. At the end of this session, you got recipes of advice on how to start your system’s observability. Remember the first recipe, observability, is not troubleshooting. It has a different purpose.
Testivator Session Score
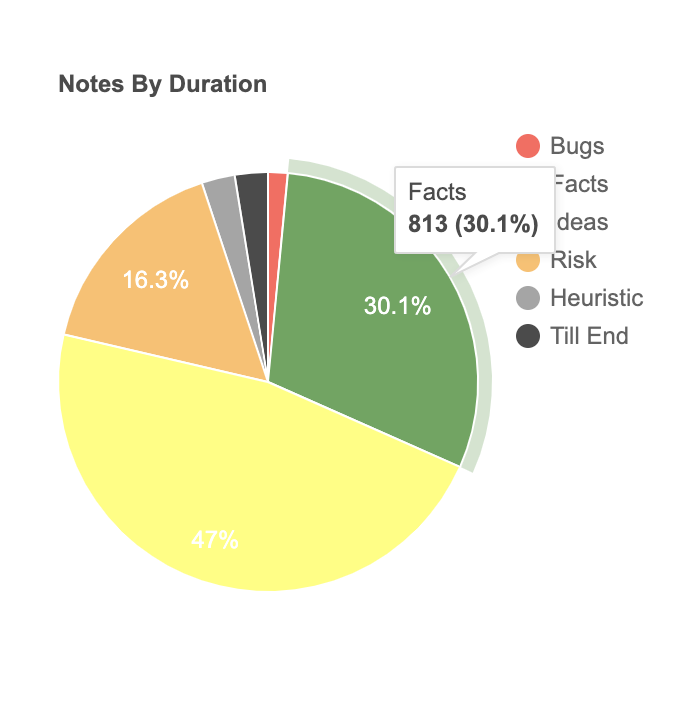
For this session, I was using the Testivator Mobile application. I took 39 notes and 10 screenshots.
Here are note types by duration. Till the end is 2.6 %, and it is the ratio of duration from last note to session end and session duration.

Comments are closed.