

TL;DR
In 2020 my hometown Zagreb was hit by two earthquakes. In this post, I will try to sublime how an earthquake works and why we can not predict earthquakes.
Zagreb 2020 Earthquakes
At approximately 6:24 AM CET on the morning of 22 March 2020, an earthquake of magnitude 5.3 Mw, 5.5 ML, hit Zagreb, Croatia, with an epicenter 7 kilometers (4.3 mi) north of the city center (Wikipedia).
At approximately 12:20 PM CET (11:20 UTC) on 29 December 2020, an earthquake of magnitude 6.4 Mw (6.2 ML) hit the Sisak-Moslavina County, Croatia, with an epicenter 3 km (1.8 mi) west-southwest of Petrinja.[Wikipedia]. That was 50km from Zagreb city center.
What Is An Earthquake?
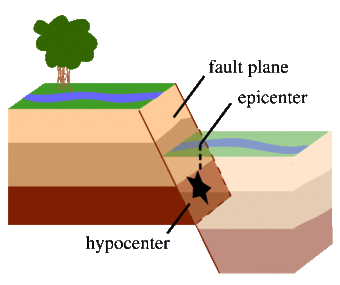
An earthquake happens when two blocks of the earth suddenly slip past one another [source].
What Is A Fault Plane?
The surface where they slip is called the fault or fault plane [source].
What Are Hypo And Epi Centers?
The location below the earth’s surface where the earthquake starts is called the hypocenter, and the location directly above it on the surface of the earth is called the epicenter [source].
What Is Foreshock?
Sometimes an earthquake has foreshocks. These are smaller earthquakes that happen in the same place as the larger earthquake that follows. Scientists can’t tell that an earthquake is a foreshock until the larger earthquake happens. Petrinja earthquake did have foreshock, and the Zagreb earthquake did not have it [source].
What Is Mainshock?
The largest main earthquake is called the mainshock. Mainshocks always have aftershocks that follow. These are smaller earthquakes that occur afterward in the same place as the mainshock. Depending on the mainshock’s size, aftershocks can continue for weeks, months, and even years after the mainshock!
After the Zagreb earthquake, we had aftershocks for almost six months [source].
What Causes Earthquakes And Where Do They Happen?
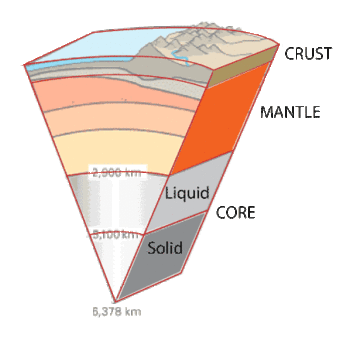
The earth has four major layers: the inner core, outer core, mantle, and crust. The crust and the top of the mantle make up a thin skin on the surface of our planet.
But this skin is not all in one piece – it is made up of many pieces like a puzzle covering the earth’s surface. Not only that, but these puzzle pieces keep slowly moving around, sliding past one another and bumping into each other.

We call these puzzle pieces tectonic plates, and the plates’ edges are called the plate boundaries. The plate boundaries are made up of many faults, and most of the earthquakes around the world occur on these faults. Since the plates’ edges are rough, they get stuck while the rest of the plate keeps moving. Finally, when the plate has moved far enough, the edges unstick on one of the faults, and there is an earthquake [source].
Tectonic Plates
Here is World divided into tectonic plates:
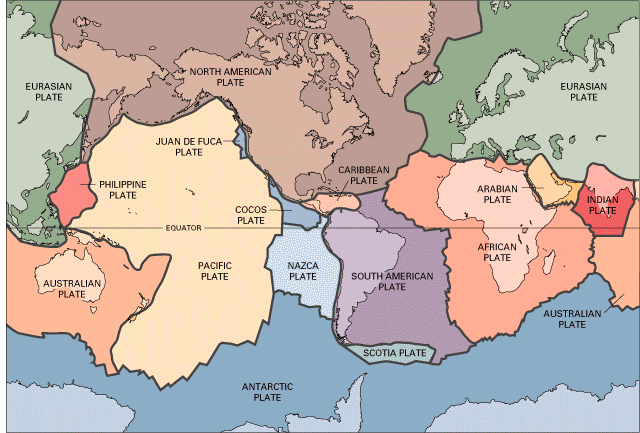
Note that Croatia is at the border of the African and Euroasian plates.
Here are European tectonic plates:
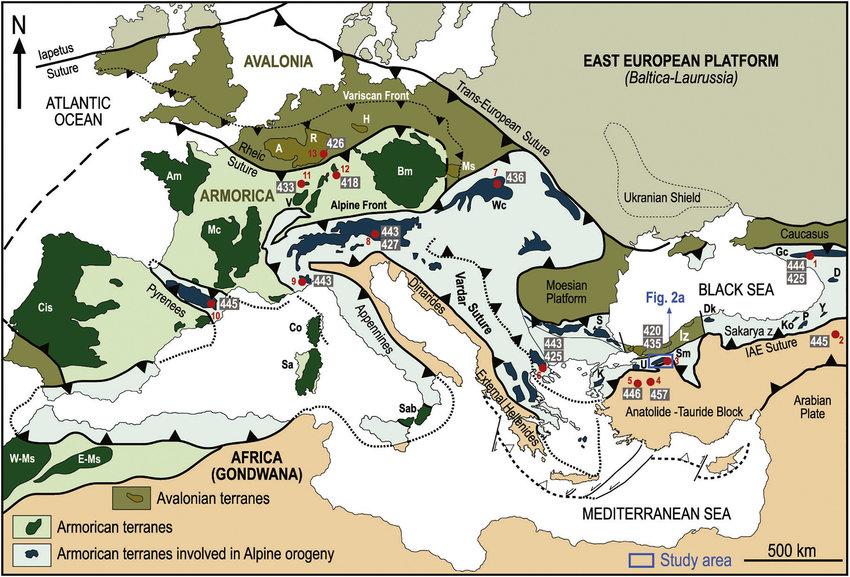
Note that Zagreb is the north side of the border that goes along Dinarides mountains.
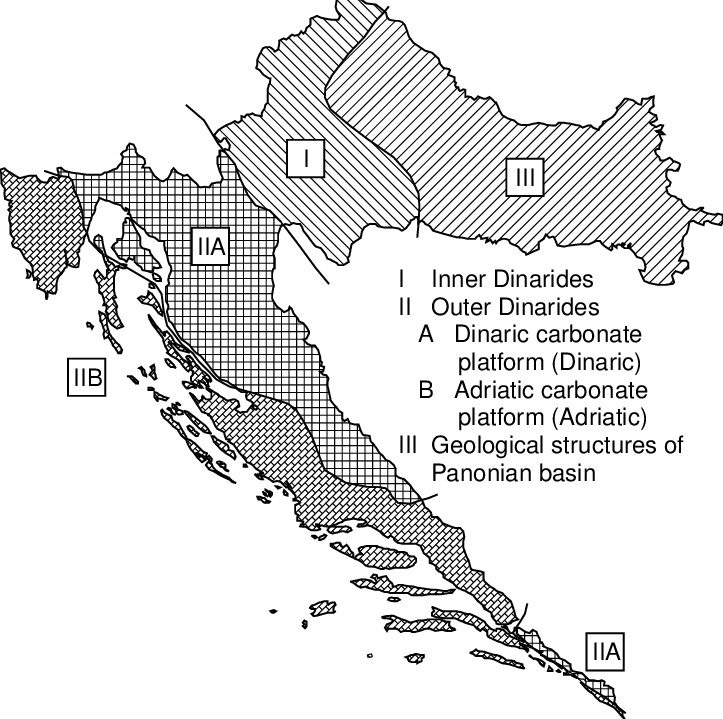
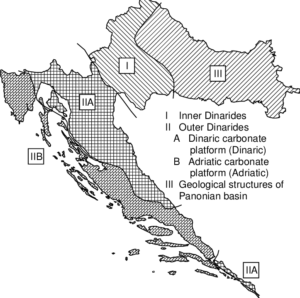
Here is a map of Croatian tectonic plates:
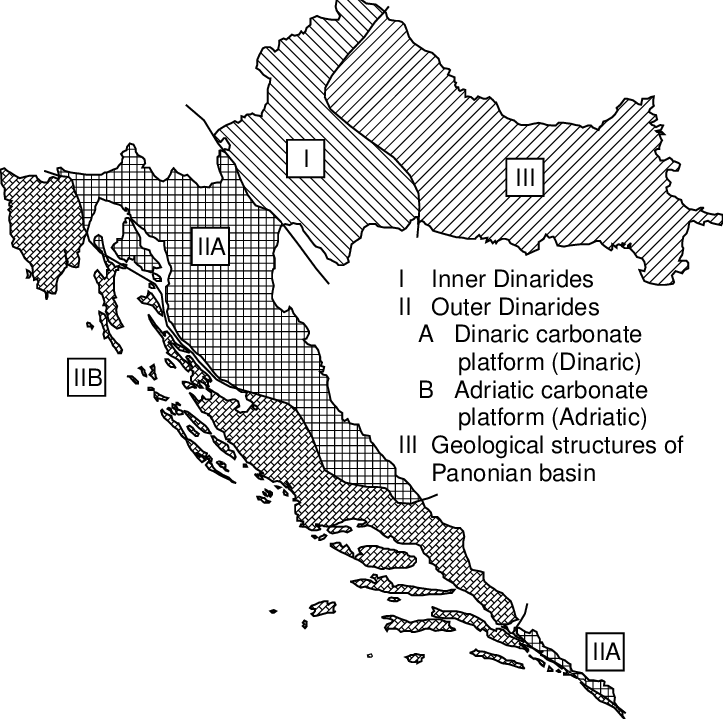
Note that Zagreb is in the center of the Inner Dinarides plate.
Why does the earth shake when there is an earthquake?

While the edges of faults are stuck together, and the rest of the block is moving, the energy that would normally cause the blocks to slide past one another is being stored up. When the force of the moving blocks finally overcomes the friction of the fault’s jagged edges, and it unsticks, all that stored up energy is released. The energy radiates outward from the fault in all directions in seismic waves like ripples on a pond. The seismic waves shake the earth as they move through it, and when the waves reach the earth’s surface, they shake the ground and anything on it, like our houses and us [source]!
How are earthquakes recorded?
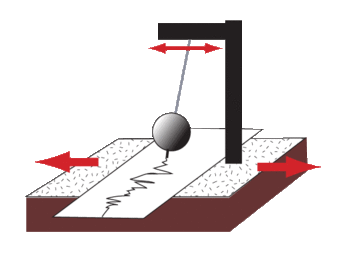
Earthquakes are recorded by instruments called seismographs. The recording they make is called a seismogram. The seismograph has a base that sets firmly in the ground and a heavyweight that hangs free. When an earthquake causes the ground to shake, the seismograph shakes base, but the hanging weight does not. Instead, the spring or string that it is hanging from absorbs all the movement. The difference in position between the shaking part of the seismograph and the motionless part is recorded [source].
How Can Scientists Tell Where The Earthquake Happened [source]?
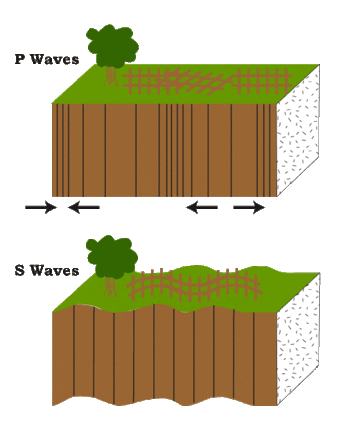
An earthquake generates two waves, P and S waves.
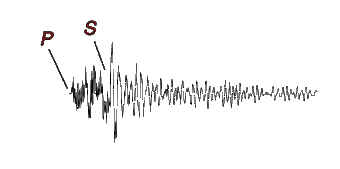
If we compare earthquake to lighting, the P wave is light from lighting, while the S wave is thunder’s sound. P travels faster. Detection difference helps scientists to determine how far the earthquake was from the seismograph.
But how to determine the actual location? For that, we need to read from at least three seismographs, and then we can apply the
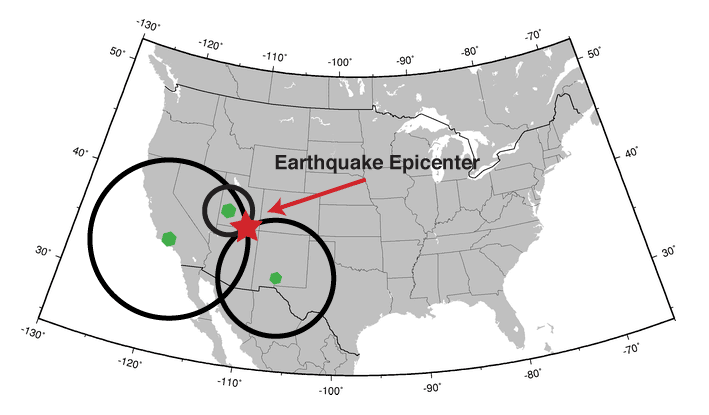
Triangulation method.
Testing In Production
I live in a building since 2008. It was built to withstand an 8.0 M earthquake.
The first earthquake caught me asleep. It had woke me, and I experienced only the last ten seconds of the tremor. The only damage was a few broken figures. Glass case with figures produced noticeable sound. The sound alarm was triggered by a nearby bank office, and the power transformer for my building was automatically shut off building from the power grid.
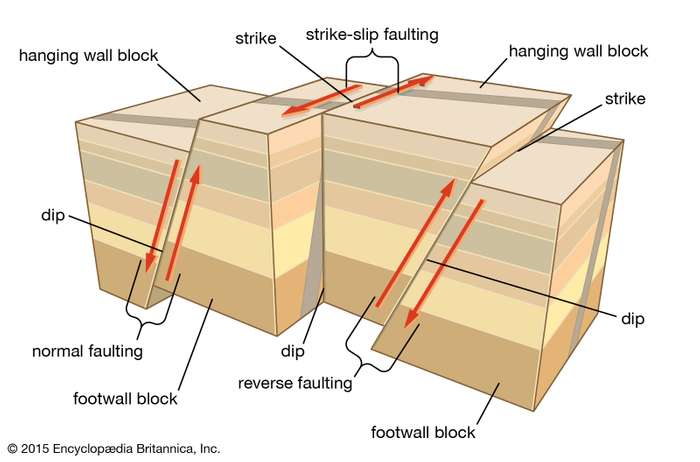
The earthquake type was the dip-slip fault of the reverse type.
The sensation of the second earthquake was different. I noticed an amplitude of 0.5 meters for about one minute. Just one figure fell on the ground without any damage. The bank alarm and power transformer did not react and the Glass case did not produce any sound.
The earthquake type was the stripe-strip fault.
What To Do?
It is not possible to predict the earthquake’s time, only that it would happen in the future with some value of probability. You can only check how close is your town to any of the local tectonic plates and be sure to know what to do during the earthquake.

Comments are closed.