

TL;DR
This post is about regular expressions and how case sensitive has a totally different meaning from my heuristics.
A regular expression is a powerful tool in pattern matching. Regular expressions look very scarry, for example, this is a regular expression for valid email address:
^[a-zA-Z0-9.!#$%&'*+/=?^_`{|}~-]+@[A-Z0-9.-]+\.[A-Z]{2,}$
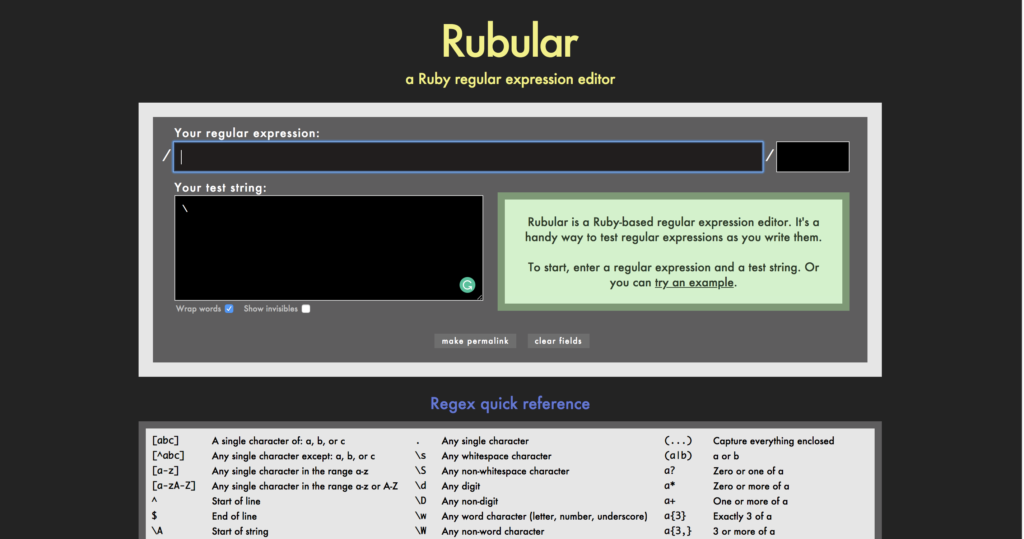
This is the reason why I avoided regular expressions for a very long time. Until the tool showed that helped me to understand and test regular expressions. It is rubular.com.
Despite the tool, I regular expression heuristics that failed. In regular expressions, A-Z means following character range:
A, B, C, D, E, F... Z
a-z is:
a, b, c, d, ....z
But what is A-z? My heuristic was:
A, B, C, D, ..., Z, a, b, c, d, e, f,....z
But this is wrong because the character range in regular expressions is:
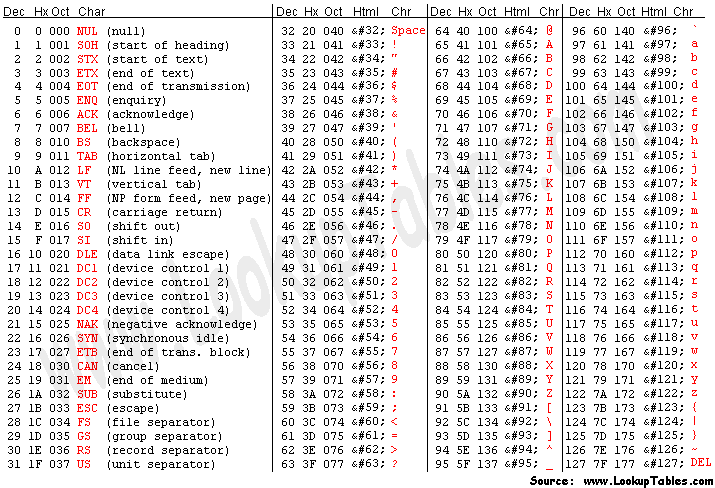
Characters from A to Z in ASCII codes!
For that, A-z also includes characters [ \ ] ^ _ `
Bug
A-z was part of a regular expression that checks user input for the uploaded file path. To avoid path traversal attacks, the file path could only contain letters. But using A-z, we allowed none letter characters. The problem is \ that could cause path traversal on Windows. Luckily, we run servers on the Unix platform where folder separator is /.
A-z issue was discovered by the developer, so quality is owned by the whole team.
