


TL;DR
Currently, I am reading two books: Taking Testing Seriously by Michael Bolton and James Bach, and Build a Large Language Model from Scratch by Sebastian Raschka.
I learned about Build a Large Language Model from Scratch from a blog post by Giles Thomas, Writing an LLM from Scratch. He follows a learning paradigm where he reads a book, converses with an LLM about things he does not understand, and then writes a blog post about it.
I started reading his blog posts, but quite soon I felt lost. That was the moment to pivot.
I bought the book (there is also an additional book with questions and exercises). My approach is now the following: read a chapter, write my notes with Botie, answer the questions from the chapter, and ask ChatGPT about anything I do not understand related to the questions or answers. Then I move on.
The book uses Python, but my goal is to use Elixir, as Elixir has good support for machine learning.
Let’s start.
What is primary difference between deep learning and machine learning?
This is the first question that should help us to enforce what we learned in chapter one. Why deep learning in particular? Because large language models are product of deep learning.
Deep learning does not require manual feature extraction, while traditional machine learning does.
For me, this raised a lot of questions, so I asked ChatGPT the following:
Please elaborate on what deep learning is, what traditional machine learning is, what feature extraction means, and where features are extracted from.
1️⃣ What is Traditional Machine Learning?
Traditional machine learning (ML) refers to algorithms like:
- Linear Regression
- Logistic Regression
- Decision Trees
- Random Forests
- Support Vector Machines (SVM)
- k-Nearest Neighbors
I have only heard about Supported Vector Machines (SVM)
How it works (high level)
Humans design features => The ML algorithm learns patterns from those features => The model makes predictions.
The key point: the model does not learn directly from raw data.
It learns from features created by humans.
Example: Email spam detection (traditional ML)
Raw data:
"Win money now!!! Click here"
You (the human) decide what matters (the features of spam):
- Number of exclamation marks
- Presence of words like “win”, “free”
- Length of the email
- Ratio of uppercase letters
You convert the email into numbers:
[exclamation_count=3, contains_free=1, length=24, uppercase_ratio=0.42]
➡️ These numbers are features
➡️ The ML model only sees numbers, not text
This was ChatGpt explanation. Now I understand what is traditional machine learning, what is feature, and how humans extracted features from input data (in example, this is text).
2️⃣ What is Feature Extraction?
Feature extraction is the process of converting raw data into meaningful numerical representations that a machine learning model can understand.
Important properties:
- Done before training
- Designed by humans
- Highly domain-specific
- Often requires expert knowledge
Where do features come from?
From raw data, depending on the domain:
| Domain | Raw data | Example features |
|---|---|---|
| Text | Sentences | Word counts, TF-IDF, n-grams |
| Images | Pixels | Edges, corners, textures |
| Audio | Sound waves | Pitch, MFCCs |
| Finance | Transactions | Averages, volatility |
| Medicine | Scans | Shapes, intensities |
Visualisation of traditional pipeline
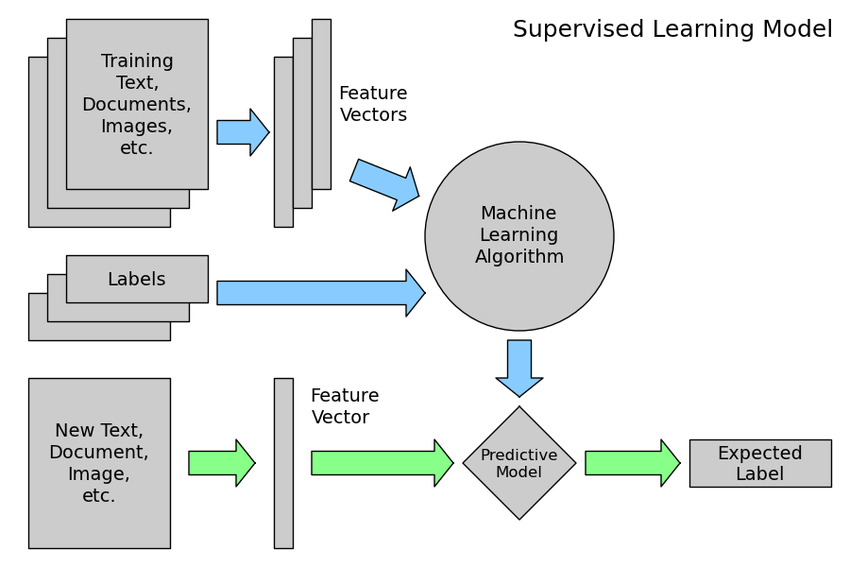
3️⃣ What is Deep Learning?
Deep learning is a subset of machine learning based on neural networks with many layers (deep neural networks).
Examples:
- Convolutional Neural Networks (CNNs)
- Recurrent Neural Networks (RNNs)
- Transformers (used in LLMs)
Core idea is very simple: the model learns the features by itself directly from raw data. No manual feature engineering.
Wait, what, data scientist are out of job!?
Example: Email spam detection (deep learning)
Raw data:
"Win money now!!! Click here"
Instead of hand-crafted features:
- The text is tokenized
- Converted to embeddings
- Passed through multiple neural network layers
Each layer learns something progressively more abstract:
- Layer 1: characters / tokens
- Layer 2: word patterns
- Layer 3: phrases
- Layer 4: intent (spam vs not spam)
➡️ Feature extraction is learned automatically
And now something completely different.
4️⃣ Why is this called “deep”?
Because features are learned hierarchically:
-
Early layers → simple patterns
-
Middle layers → more complex patterns
-
Deep layers → abstract concepts
Raw Data → Neural Network (many layers) → Prediction
No explicit “feature engineering” step.
6️⃣ Why this matters for LLMs
Large Language Models:
- Take raw text
- Learn grammar, syntax, meaning, facts
- Without any manually defined linguistic rules
Humans do not define:
- What a noun is
- What sarcasm is
- What sentence structure is
The model discovers these patterns through deep learning.
This is important part. LLM does not know what noun is, but it recognizes word patterns that are noun. We can say that it knows what is noun. Is this intelligence? Is deep neural network mimicking our brain?
7️⃣ One-sentence intuition (very important)
Traditional ML learns from features humans design.
Deep learning learns the features itself.
And that wraps first question from chapter one. There are important fundamentals that we need to know in order to build ChatGpt from scratch.
